

Diagnosing your current AI/ML program and how to improve its outcomes
By Gokhan Metan, Ph.D., Vice President of Enterprise Data Science and Engineering, Centene Corporation
Two decades ago, when the term Data Science wasn’t even coined yet, I was writing my Master thesis on applying machine learning models to manufacturing systems, known as Job Shop manufacturing. My models, coded natively in Java, would consist of simulation, machine learning and optimization algorithms. Requiring a lot of experimentation for my thesis and lacking the type of parallelization and compute power at the time, I had to reserve 3 computer laboratories at my university, each equipped with 35 Pentium IV PCs for a duration of 2 months to generate the computations for my work. I had to load each computer manually 3 times a day using a floppy disk to install my experiments. That is 18,900 times insert/eject floppy disk during two months of intense computational work! Sounds painful, doesn’t it?! And that is precisely my point for starting this article with this story. Because the story hasn’t changed much in the last two decades despite the advancements in technology, cloud becoming more main street and all the richness of data science packages in our toolbox, that we still observe our Data Scientists suffering from similar limitations to get their day-to-day work. As leaders in the field, diagnosing and removing these bottlenecks significantly contribute to the value-add of data science programs.
Senior leaders are naturally interested in running modern and effective Data Science programs in today’s highly competitive business environments for variety of reasons. In addition, it is also in the best interest of the data science organization to deliver up to the expectations given the high cost of data science talent in today’s labor market as well as the level of investments typically required to run a modern data science program. Despite this alignment of incentives, many data science organizations suffer from justifying its value or delivering up to its expectations. Obviously, there are various reasons that contribute to such poor outcomes, among which are organizational politics, misalignment among departments so on and so forth. However, in this discussion we focus on potential challenges that more or less fall within the span of control of the analytics executive running the AI/ML program for the company. The awareness around these challenges, however, should be shared across all leaders, who are one way or another touching to or benefiting from the AI/ML solutions created within the company.
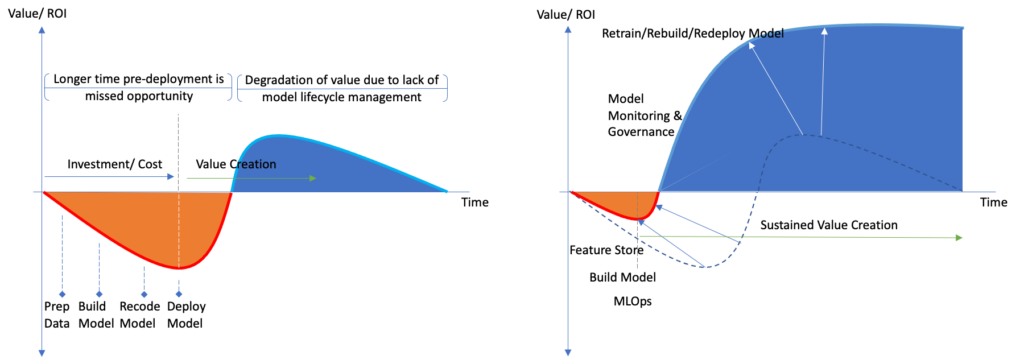
Table 1 attempts to capture these challenges, assess the criticality level for the success of data science organization, as well as at what maturity level of the program the challenge becomes more visible and critical for the organization. We also provide a diagnostic of the challenge to best describe its characteristics and a simple, yet effective, “smell test” to catch the symptoms of the problems. Any data science leader faces many, if not all, of these challenges throughout his/her tenure leading the AI/ML program. These challenges are opportunities to transform the data science program from an inefficient one (i.e., left chart in Figure 1) to a well-oiled value generating program (i.e., right chart in Figure 1). Once mastered, the resulting AI/ML operations will consistently outperform competitors’ programs, yielding industry leading returns from each commissioned AI/ML model.
| Challenge | Criticality | Maturity | Diagnostic |
| Value Adding Business Use Cases | High | Low/Med | High value business use cases aren’t identified, business leader buy-in for AI/ML solutions is lacking. Data Scientists are not given clear problem statements, realistic objectives, and/or operational parameters to produce successful AI/ML implementations. As a result, data science teams spend energy in endless modeling cycles, doing data science for the sake of data science. Smell Test: Data scientist spending months on relentlessly iterating on the first release of the model before the first model deployment. |
| Access to Right Data Assets & Lack of Data Science Feature Store | High | Low/Med | Data Scientists have frequently run into barriers in getting the data they need. Data assets are siloed, heavily structured in traditional warehouses typically created for reporting/BI purposes, AI/ML infrastructure is antiquated and lack supporting semi-/un-structured data assets. As a result, it takes significant afford to get right data assets together for modeling, and the value of data assets is watered down by the high degree of upstream data cleansing/structuring happened without data scientist involvement. Smell Test: Data scientist spending 60%+ of their time on data issues and yet the model performances are average at best. Deployment of models frequently run into delays due to data not mapped in prod environment. |
| Compute and Storage Limitations | Med | Med/High | Data Scientists are limited by the resources and make choices to get around the compute and storage limitations. Compute limitations force data scientists to cut corners from model experimentation/ training, resulting in settling on suboptimal model performance. In certain situations, there are limitations elongate the development time significantly as there may be no other way. Storage limitations are the dumbest of all at our time as storage is dirt cheap and yet data scientist still suffer from it as data science infrastructure may limit their access to its use, resulting in lack of version control of data, prematurely concluded feature engineering activities and such. Model quality and delivery timeliness suffer as a result. Smell Test: Data Science team frequently runs out of gas in the model development process and timeliness are pushed out frequently. |
| Modeling Practices | Med | Med/High | Diversity of modeling techniques employed is shallow. Data Science teams throw the same technique on every business problem encountered. Teams do not experiment sufficiently in model fine tuning and optimizing for better performance. Smell Test: 90%+ model inventory is XGBoost or Logistic Regression. |
| Model Deployment (MLOps) | High | Med/High | Data Science team throws the model over the fence for IT teams to refactor/recode. Models are not containerized, causing various deployment breakdowns such as version controls, package inconsistencies and such. Productionizing models take significant effort and is a black box to data scientists. Productionized models can’t be easily rebuild/refit/redeployed. Monitoring the performance of the models are weak to nonexistent. Models unexpectedly breakdown and come offline, or in severe situations operate but feed wrong results to downstream operations until caught by pure luck. Smell Test: Models in production is akin to light sucked in to a blackhole. |
| Model Risk and Lifecycle Management | High | High | Models that made to production are now mostly left alone to their fate until a. something breaks down seriously and cause disruption, b. model outputs result in an adverse business outcome, in certain cases resulting in significant financial and/or reputational loss, c. model is retired. Model telemetry is not captured as part of the production code, or telemetry is subpar to flag model risks adequately. At best, this lack of model monitoring and governance results in rapid degradation of potential business value that could be extracted from the models, resulting in the second half of the curve on the left side in Figure 1 (i.e., blue region – rapid degradation of value). Smell Test: There is no model monitoring or model health reporting regularly reviewed by leadership – after take off you are flying blind! |
We should also recognize, taking action on all of these challenges at once is no small task. For this reason, we recommend leaders to prioritize their most pressing needs and invest in those areas first. For instance, in one year we have decided to invest in Feature Store, Model Risk and Lifecycle Management as the priority areas for investment, particularly because these areas represent the greatest opportunity for improvement for our program. At the time of this decision, we already had good solutions in place that solved for compute and storage, modeling practices were diverse enough, already instituted solid MLOps solutions, and had a solid backlog of well-defined business use cases. Lack of feature store and limitations to access to certain data assets introduced friction points for the data science team in our development of some of the new business use cases in our pipeline. We estimated that investing in feature store would increase our team productivity by 30-40% in the mid-to-long run by cutting the time for preparing data for modeling. We also identified model lifecycle management and governance as an investment area to maintain a sustainable value creation from our model inventory. We estimate another 30-40% improvement in value creation for the business through constant monitoring and automatically refitting models that are starting to decay. In addition, our improved model governance will mitigate variety of risks, strengthening our reputation to our auditors and government regulators.
The field of AI is evolving at a pace that brings amazing solutions to our lives every day. As consumers of these solutions, we are spoiled than ever, demanding more and more products that are smarter and easier to use in our lives. Companies who will succeed in this environment will have less room for errors, will need shorter development cycle times, and better return on investment to sustain innovation. Diagnosing the efficiency of AI/ML programs and improve its outcomes will become table stakes in very short order.